You might not need * is a fairly old project and started off as a joke. I registered the domain in 2014 and I let it sit there for 3 years before doing anything with it, as you do...
If you've been around when jQuery was the most discussed library and browsers api started getting better, you might have heard of You Might Not Need jQuery, a brilliant website with the goal of providing vanilla solutions to the problems jQuery was solving.
I set my mind in providing a similar experience for Lodash and I started off by forking their repository. I soon realised that I couldn't move fast enough in that codebase: it's all in coffescript, jade and stylus, which I imagine were sensible choices for the person or team working on it, but not something I was comfortable with.
So I did my own thing. I chose React Static because it was quite straight forward to work with, would generate a static output (as the name suggests) and had an API to write custom plugins.
Taking advantage of this last feature, I created a plugin that allowed me to load content from specific folders and parse it as raw text
// node.api.js
export default () => ({
webpack: config => {
// [...]
config.module.rules.push({
test: /\/content\/(.*).js$/,
use: 'raw-loader',
})
return config
},
})
There's more to it – for example the bit to load markdown descriptions, you can find the full plugin in the repo – but by adding those few lines, the js files content gets loaded in a way perfect to be injected in a React HighLight.js component.
I picked that component despite being rather old, because it offers the opportunity to optimise the bundle size by adding a few more lines to the webpack config, which was exactly what I was fiddling with at the time.
This method of loading files also works pretty well with structuring the content as the file path can be used for that purpose.
So each domain (array, collection, date, function, etc etc) in which Lodash groups its own methods becomes a parent folder for the appropriate children methods folders. Each method folder contains 4 files: lodash.js, spec.js, vanilla.js and notes.md – the names are rather self-explanatory.
After a while I also created a script that would scrape the Lodash documentation and fill the example and the notes appropriate content.
const getLodashDocs = async method => {
const { data } = await axios.get('https://lodash.com/docs/4.17.15')
const $ = cheerio.load(data)
return {
description: $(`#${method}`).siblings('p').next().html(),
example: $(`#${method}`)
.siblings('.highlight')
.find('div')
.toArray()
.map(
item =>
`// ${$(item)
.text()
.replace(/\s+/g, ' ')}`
)
.join('\n'),
}
}
This gets triggered as part of a stepped guided process built with Inquirer.
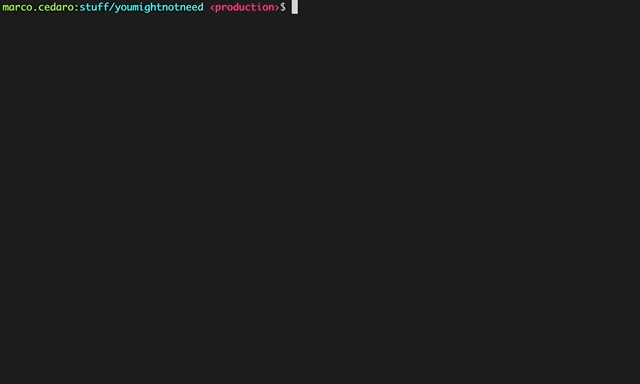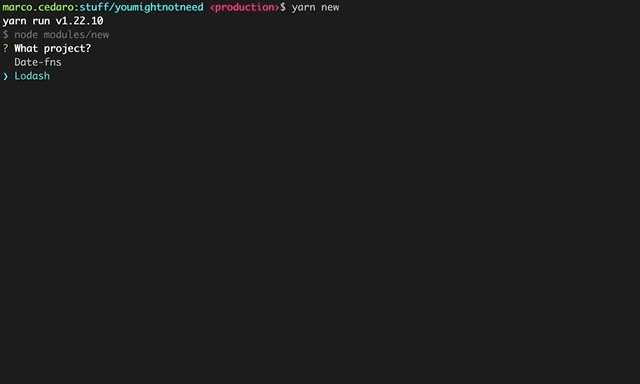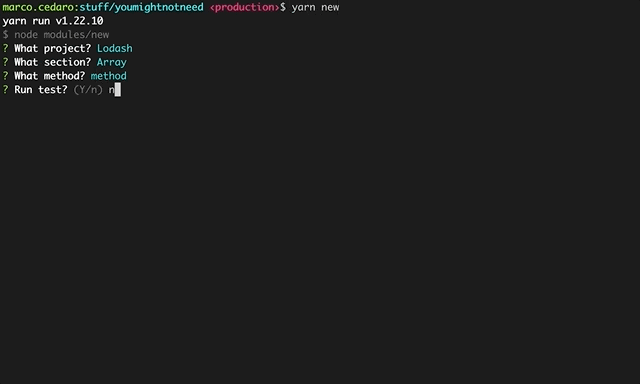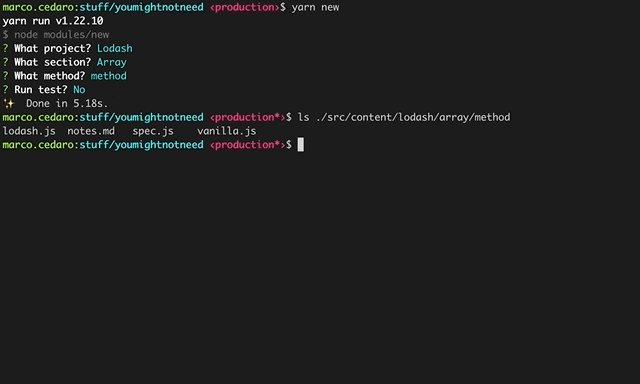
This was surely for my benefit, but also having in mind the goal of a smooth onboarding for people who were willing to contribute. Goal that was supported by taking advantage of the niceties of modern development flows, ie: git hooks and prettier to avoid having major styling issues, codecov to enable visual representations of test coverage in PRs – the content is 100% tested, which makes the website the most comprehensive unit tested collection of Lodash methods reimplemented in vanilla js – and other few bits and bops.
Objectives
As far as the project went, though, the main goal was not to create a drop in replacement for Lodash, but to provide a learning platform.
One of the first things that got added were the links to MDN for all the methods used in each vanilla version, including the ones that nowadays some of us kinda give for granted; and links to Regexr for each Regex needed (and yes, yes: I know) so that people could fiddle with them and look at the explanation tab.
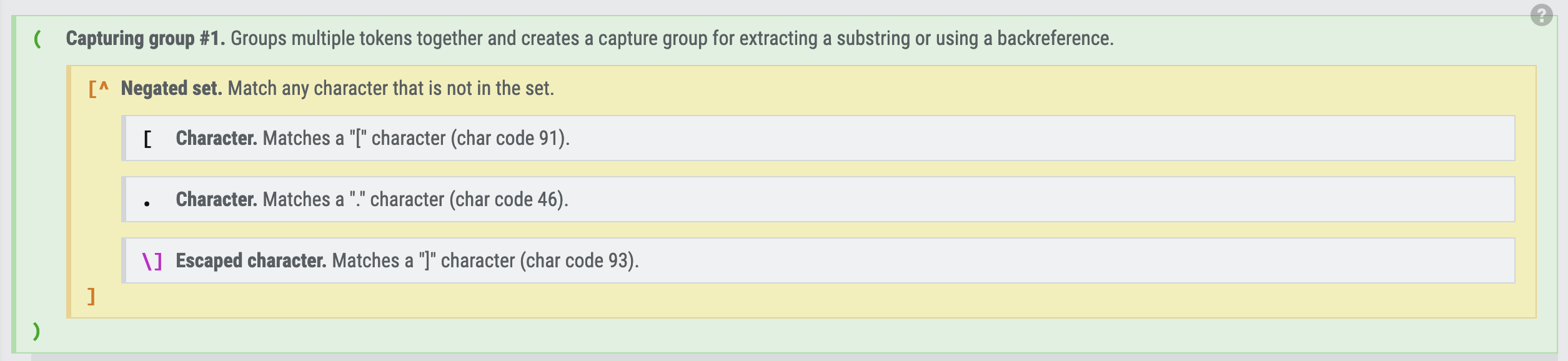
a[0].bar.c.But I always felt that the code comparison, no matter how clear and despite how many references were provided, was a bit dry.
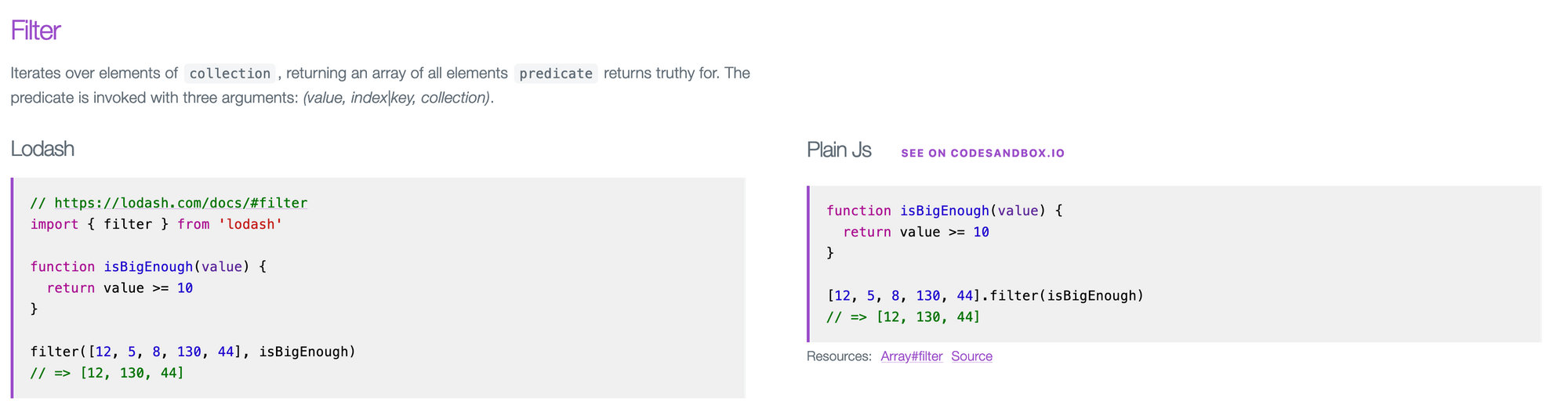
filter method looks likeSo I added the button you see in the screenshot, the "see on codesandbox.io".
This is the most recent development, and I'm kinda proud of it, and pretty much the whole reason I ended up writing this post so late after the project was launched
Codesandbox
Codesandbox.io provides effectively a sandboxed code editor which can be embedded anywhere, and can be "prefilled" with content.
The codesandbox api documentation is incredibly clear, but TL;DR, there's an npm module that exposes a getParameters method. By invoking it with an object having the following schema
const parameters = getParameters({
"files": {
"src/index.js": {
"content": "console.log('hello!')",
"isBinary": false
},
"package.json": {
"content": {
"dependencies": {}
}
}
}
})
it returns a compressed lz-string which can be appended to the api endpoint.
const url = `https://codesandbox.io/api/v1/sandboxes/define?parameters=${parameters}`;Opening it in the browser (or using wget, axios or whatever else) redirects to the workspace matching that parameter, creating it for you if it doesn't exist.
The actual script used in YMNN doesn't differ much from the example above, except the content of most of the files is the result of an fs.readFileSync – being run at build time it doesn't quite matter – and some dependencies.
const { getParameters } = require('codesandbox/lib/api/define')
const fs = require('fs')
const glob = require('glob')
const packages = require('../package.json').dependencies
const endpoint = 'https://codesandbox.io/api/v1/sandboxes/define'
const fixFileName = (frw, file) => file.replace(`./src/content/${frw}/`, '')
module.exports = path => {
// as mentioned the folder structure is meaningful to the content
const [, frw] = path.match(/src\/content\/(.+)\/(.+)\/(.+)/)
const fileList = glob.sync(`${path}/*.js`)
const files = fileList.reduce(
(acc, file) => ({
...acc,
// fixFileName removes the deep nesting to simplify the file structure
[fixFileName(frw, file)]: {
content: fs.readFileSync(file, 'utf8'),
isBinary: false,
},
}),
{}
)
const parameters = getParameters({
files: {
...files,
// prettier is well supported by codesandbox.io and it would
// maintan the style with a matching config
'.prettierrc': {
content: fs.readFileSync('./.prettierrc', 'utf8'),
},
'package.json': {
content: {
// the dependencies are matching the real ones imported
// in the package.json
dependencies: {
[frw]: packages[frw],
'@babel/runtime': '7.15.4',
},
},
},
},
})
return `${endpoint}?parameters=${parameters}`
}
On top of this script, there's a CLI script which takes file paths as arguments, gets the endpoint for the corresponding method folder and, if it has changed from a reference file, triggers a call to the endpoint with axios.
The resulting request.res.responseUrl is the canonicalUrl of the new made sandbox, which gets stored in another json file, the one actually imported in the website. NB: The reason for the 2 steps check is to allow to run the script on all methods and once and actually use axios only if the payload changes, otherwise the would be no need for a reference file in the first place.
I didn't want anyone to have to run this manually on their local machine to open a PR and that's where Github actions came in handy.
If you haven't had the opportunity to work with them, they are pretty much a CI environment that can be triggered by Github events. I might have oversimplified a bit, but broad strokes it's not too far from the truth.
name: Update codesandbox references
on:
push:
branches-ignore:
- production
The opening of my update-codesandbox.yml is pretty standard: name of the action, event triggering it – with a filter excluding the production branch as it should run only in PRs, no one should push changes to the main branch directly anyway.
jobs:
triage:
runs-on: ubuntu-latest
outputs:
content: ${{ steps.changes.outputs.content }}
files: ${{ steps.changes.outputs.content_files }}
steps:
- uses: actions/checkout@v2
- uses: dorny/paths-filter@v2
id: changes
with:
base: ${{ github.ref }}
list-files: shell
filters: |
content:
- 'src/content/**/*.js'
The jobs section contains 2 jobs. The first is the triage, and if we start to look at the steps first, we'll notice it uses 3rd party actions to perform operations, composing its own steps. By looking more in detail, it uses actions/checkout to check out the Github repo, and then it uses that dorny/path-filter. The latter provides an output, exposed a few line above in the outputs section of the job. It's a boolean and a list of files, populated if the PR contains any change matching the path in the filters.
At every push to a branch containing content changes, this job would return an output property content with a true value and a files list containing the path of the files changed (in a format compatible with shell).
codesandbox:
needs: triage
if: ${{ needs.triage.outputs.content == 'true' }}
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: browniebroke/read-nvmrc-action@v1
id: nvmrc
- uses: actions/setup-node@v2
with:
node-version: '${{ steps.nvmrc.outputs.node_version }}'
cache: 'yarn'
- run: yarn install --prefer-offline --frozen-lockfile
- run: |-
node ./modules/create-code-sandbox-cli ${{ needs.triage.outputs.files }}
- uses: swinton/[email protected]
env:
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
files: |
src/code-sandbox-refs.json
src/code-sandbox.json
commit-message: Updating codesandbox references
ref: ${{ github.ref }}
The second job, is the one actually updating the content: it needs triage to execute before and it will only run if the output property content of the triage job is true.
If these requirements are fulfilled, this job would checkout the repo, setup node with the version required by nvm, install all the dependencies and then run the script to create the already mentioned json files.
At that point it uses the Verified Commit action to push the changes back to the branch.
The json is the loaded asynchronously by taking advantage of React.Suspense and React.lazy because there's no point in bundling a big file when users might never click that button to show the embed, with the tests running and the code editable.
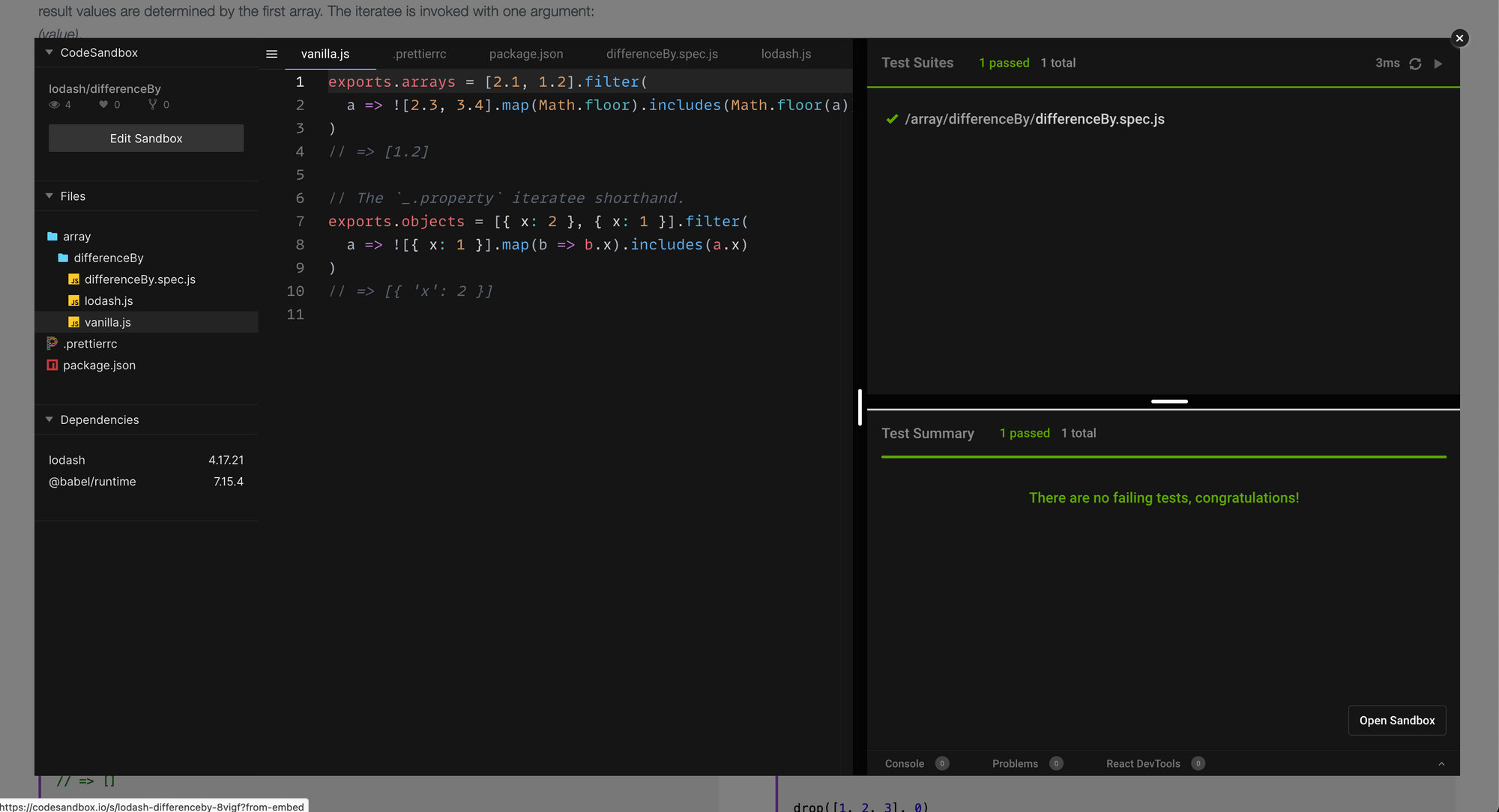
The excitement of having this feature out is probably not going to be blessed by an increase of traffic or anything like that, but it was interesting to introduce Github actions, and I think soon enough the tests should end up there too: right now they are on Travis, but less tools I need to deal with the better.
The Code
You Might Not Need: https://github.com/cedmax/youmightnotneed/